Learning based clustering of streamed process data for the efficient modelling and prediction of characteristics in milling processes based on the integration of domain knowledge
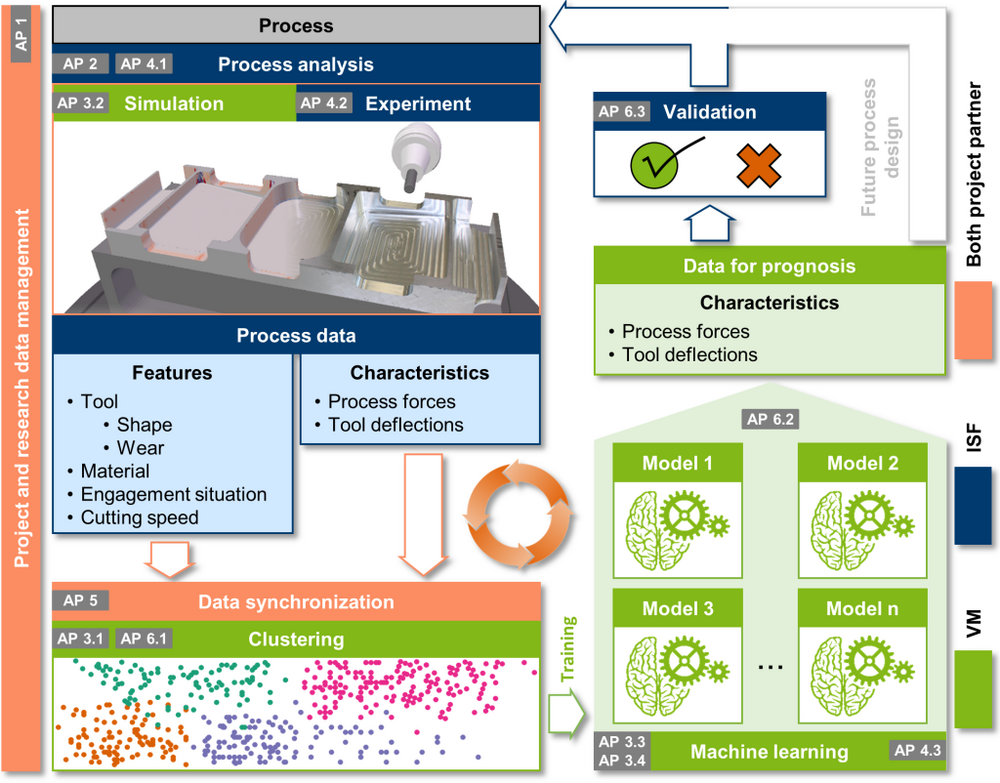
The research project "Learning based clustering of streamed process data for the efficient modelling and prediction of characteristics in milling processes based on the integration of domain knowledge" (ClusterSim) is a collaborative project between the Institute of Machining Technology of the Department of Mechanical Engineering and the Virtual Machining group of the Department of Computer Science and investigates the development and evaluation of a novel approach for cluster-based modeling and prediction of machining process characteristics by incorporating machine learning (ML) methods. However, this is not intended to be a "black box" application. Rather, expert knowledge is included as an accuracy and efficiency enhancing resource. For this purpose, process models and the knowledge of the relationships formalized therein, in combination with technological expertise, represent a central "enabling technology". Time series data from experimental investigations as well as from geometric physically-based process simulations are to be analyzed, evaluated and provided for the prediction of characteristics of other process configurations by means of the application of ML methods with simultaneous integration of technological expert knowledge. Expert knowledge on technological boundary conditions and interrelationships will be used in order to be able to design the analysis and ML methods as application-specific as possible and thus efficiently. Therefore, a basis for the characterization, evaluation and prediction of machining processes is to be created.
The central foundation for the realization of the project-specific goals is explorative data mining, which is used to group milling operations into classes on the basis of characteristics for each high-resolution sampling of the process data by applying clustering methods. The result of the clustering represents an assignment of each feature vector of the time series to a class. Subsequently, ML regression models are learned for each class. These are used to predict process characteristics for features for each corresponding class. In order to represent this relationship, measured or simulated process characteristics are acquired for each feature vector. Within the scope of the project initiative, the focus will initially be on process dynamic characteristics and their effects on surface quality of the workpiece.
In addition, a suitable strategy for transparent and sustainable research data management will be established during the project. In this context, data storage, structure, formatting and labeling are particularly important. Data is always of central importance in the context of ML methods. It is required to develop, learn, test, understand, evaluate, and evolve new methods and approaches. Thus, the lack of availability of application-specific data often inhibits new and further developments of methods. To address this issue and to contribute to increasing the availability of application-specific data sets, all process and research data generated and used in the project will be made freely available to other researchers.